全人類個人出生順位識別番号
Universal All-Humanity Individual Birth Order Identification Code

全人類個人出生順位識別番号プロジェクト報告書:
歴史的出生データに基づくユニーク識別子付与アルゴリズムの詳細分析と実装提案
I. 序論
プロジェクトの背景と目的
現代社会は、デジタル化とグローバル化の波により、個人の一意な識別が不可欠な時代へと進化しています。行政サービス、医療、教育、金融取引といった多岐にわたる分野において、個人を正確かつ普遍的に識別するシステムの需要は増大しています。しかし、既存の識別システム、例えば国籍に基づくIDや社会保障番号などは、国境を越えた連携や生涯にわたる一貫性において課題を抱えています。特に、個人がその本質的な存在としてではなく、国籍、出生地、あるいはその他の属性によって一括りに評価されがちな現状は、社会の分断を助長する一因ともなっています。本来、人間には本質的な属性は存在せず、一人ひとりがその唯一無二の存在として評価されるべきであるという根源的な問いが、このプロジェクトの出発点にあります。
本プロジェクトは、これらの課題を解決するための革新的なアプローチとして、「全人類個人出生順位識別番号」という概念を提案します。これは、個人の出生順序に基づき、地球上の全ての個人に一意かつ普遍的な識別子を付与するという壮大な試みです。この識別子は、生年月日、出生時刻、出生地といった普遍的な出生情報のみに依拠し、国籍や居住地といった変動要素に左右されない永続的な識別を可能にします。本レポートの目的は、このユニーク識別子付与アルゴリズムの設計思想、歴史的出生データに基づく推定方法、Google Apps Scriptを用いた具体的な実装アプローチ、およびその潜在的な社会的意義と今後の課題について詳細に分析し、その実現可能性と堅牢性を検証することにあります。
全人類個人出生順位識別番号の概念と意義
「全人類個人出生順位識別番号」とは、地球上で誕生した全ての個人に対し、その出生が地球上で何番目であったかを示す一意の連番(出生順位)を付与する識別システムです。この番号は、出生の正確な時空間情報(協定世界時(UTC)での出生時刻、経度)を基に決定されます。
この識別番号の導入は、いくつかの重要な意義を持ちます。第一に、これは国籍や特定の制度に依存せず、生涯にわたって変更されない普遍的な識別子となります。これにより、国際的な移動や国籍変更があったとしても、個人の識別情報が揺らぐことがなく、一貫した個人認証が可能になります。第二に、異なる国のデータシステム間での個人情報の統合・連携を容易にする可能性を秘めています。例えば、国際的な災害時の身元確認、国境を越えた医療記録の共有、グローバルな学術研究の推進など、多岐にわたる分野での応用が期待されます。第三に、この識別番号は、単なる技術的なID付与に留まらず、人類の歴史における個人の存在を時空間的に位置づけるという、より深い意味を持つことになります。これは、個人のアイデンティティの根源に迫る試みであり、その普遍性は既存の識別システムが抱える限界を超える可能性を秘めています。既存の識別子(パスポート、社会保障番号など)が国や制度に紐づくことで、国境を越えた移動や制度変更の際に複雑化し、一貫性を欠く場合があるのに対し、出生順位識別番号は、個人の「誕生」という普遍的な事象に基づいているため、これらの制約を受けません。これは、グローバル化が進む現代において、個人の「普遍的アイデンティティ」を確立する新たなパラダイムを提供する可能性を秘めていると言えるでしょう。
さらに、この識別番号の概念は、「人間一人ひとりをかけがえのない存在として捉える」という哲学を具現化するものである。親、家族、学校、仕事、社会といった様々なコミュニティの中で生きる一人ひとりが、その存在を確実に認識されるべきであるという思想に基づき、この番号は「この世にただ1人のあなた」を証明する唯一無二の形として機能する。個人はそれぞれが独立した存在であると同時に、全ての人間は人間から生まれ、人間として生きていくという、延々と続く人類の歴史の一員である。この識別番号は、個人の唯一性を尊重しつつも、全ての人間が共通の「人間」という枠組みの中で繋がっているという普遍的な事実を再認識させる役割を担う。名前や属性に依拠するのではなく、その人だけに付与された数字を「存在の証」として捉えることで、人間万歳が根底に持つ「人を人として見る」という信念を、この構想は深く体現している。
本レポートの構成
本レポートは、以下の主要なセクションで構成されます。第II章では、アルゴリズムの基礎となる歴史的出生数推定について、国連の人口統計データを活用して詳細に論じます。第III章では、ユニーク識別子付与アルゴリズムの具体的なロジックと設計思想を解説します。第IV章では、Googleスプレッドシート上でのApps Scriptを用いた実装方法と運用上の留意点について述べます。最後に、第V章では、本プロジェクトの結論、潜在的な応用、および今後の展望について考察します。
II. 歴史的出生数推定の基礎
データソースと収集方法 (UN World Population Prospects 2024データの活用)
本プロジェクトにおける歴史的出生数推定の基礎データとして、国際連合経済社会局人口部が発行する「World Population Prospects 2024 (WPP2024)」を活用します。WPP2024は、世界の人口統計に関する最も包括的かつ信頼性の高い情報源の一つであり、1950年から2100年までの年間出生数、総人口、死亡数などの詳細な推計値と予測値を提供しています。
このデータセットは、世界全体、地域、準地域、および国・地域別の詳細なデータを含んでおり、本プロジェクトの「全人類」というスコープに対応する網羅性を持っています。特に、Location code 900で示される「World」のデータは、地球全体の年間出生数を把握するために直接的に利用されます。WPP2024には、1950年から2023年までの「Estimates」(推計値)と、2024年から2100年までの将来予測のための複数の「Variant」(シナリオ)が含まれています。歴史的出生数推定には主に「Estimates」データセットの「Births (thousands)」列を用います。将来の出生数については、「Medium fertility variant」を基本シナリオとしつつ、他のバリアント(High, Low, Constant-fertility, Instant-replacementなど)も参照することで、推定の不確実性や将来的な識別番号の規模に関する感度分析を可能にします。
出生数推定モデルと仮定
WPP2024のデータは1950年以降の推計であるため、それ以前、特に近代以前の出生数については、既存の歴史人口学研究や推定モデルを参照する必要があります。本アルゴリズムでは、人口統計学の分野で信頼性の高い情報を提供している人口統計研究所(Population Reference Bureau: PRB)のコラム「How Many People Have Ever Lived on Earth?」 の推定値を参照しています。PRBは、人口統計学に関する客観的で信頼性の高いデータと分析を提供することで知られており、その推定は「科学の一部であり芸術の一部」 とされるものの、人類の歴史全体にわたる人口規模の概算を得る上で貴重な情報源となります。
PRBの推定によると、現代人類の夜明けから紀元1年(1 C.E.)までに地球上で誕生した累積出生数は約550億人 とされています。また、2022年までに地球上で誕生した人類の総数は約1,170億人 と概算されています。これらの数値は、本アルゴリズムの初期の識別番号の基礎を形成します。提供されたデータ には「年代 (A),年間出生数 (B),その年代までの累積出生数 (C)」として、349年、709年、1069年、1429年といった特定の年代までの累積出生数が示されており、これらはPRBのデータに基づく歴史人口学的な推定を反映しています。
PRBのデータには、紀元前からの特定の年代における累積出生数とベンチマーク間の出生数が示されており、例えば1200年から1650年までの450年間で12,782,002,453人が出生したことが読み取れます。このような累積人口のデータから、特定の年代における年間出生率を概算することが可能となる。これにより、1322年といったデータに直接存在しない単一の年についても、補間を通じて出生数を推定する柔軟性が確保される。これらの数値は、本アルゴリズムの初期の識別番号の基礎を形成します。
この推定モデルにはいくつかの仮定と限界があります。WPP2024データは国連の専門家による精緻な推計ですが、過去のデータには報告の限界や推計誤差が含まれる可能性があります。特に、PRBも指摘しているように、人類の歴史の99%以上において人口統計データが存在しないため、初期の推定は仮定に大きく依存します 。例えば、初期の期間における人口増加が一定であるという仮定は、実際の平均人口規模を過小評価している可能性も示唆されています 。
過去の人口動態データ分析と推移
1950年以降、世界の年間出生数は、医療の進歩や公衆衛生の改善、開発途上国における出生率の高さにより、一貫して高い水準を維持してきました。しかし、近年では先進国を中心に少子化が進み、世界全体の出生率も徐々に低下傾向にあります。産業革命以降、特に20世紀後半からの人口爆発により、地球上の累積出生数は指数関数的に増加しています。この急速な増加は、識別番号の規模が非常に大きくなることを意味し、アルゴリズムの効率性とスケーラビリティが極めて重要となります。累積出生数のトレンドを理解することは、識別番号の桁数や将来的な枯渇といった実用的な側面を評価する上で不可欠です。人口は過去から現在にかけて増加し続けており、これは累積出生数も増加し続けていることを意味します。このことから、アルゴリズムは、この膨大な累積数を効率的に管理し、将来的な出生にも対応できるような設計でなければならないことが示唆されます。
将来の出生数予測の考慮とアルゴリズムへの影響
WPP2024は、「Medium fertility variant」を最も可能性の高いシナリオとしつつ、「High fertility variant」や「Low fertility variant」など、異なる仮定に基づく複数の予測を提供しています。これらは、将来の年間出生数が大きく変動する可能性を示唆しています。アルゴリズムは、これらの異なる将来シナリオにおいても、一意性と連続性を維持できる堅牢性が求められます。特に、出生率の急激な変動や、予期せぬ人口動態の変化にも対応できる柔軟性が望ましいと言えます。
将来の出生数予測の不確実性は、識別番号システムの将来性に直接的な影響を与えます。アルゴリズム自体は出生順位を決定しますが、その総数は人口動態に依存するため、システムの設計は予測の幅を考慮に入れるべきです。WPP2024には複数の将来予測シナリオが存在し、これらのシナリオは、将来の累積出生数に大きな差を生む可能性があります。このことから、識別番号システムは、特定の予測に過度に依存せず、将来の人口規模の変動にも対応できるような、柔軟な設計思想を持つべきであることが示唆されます。例えば、識別番号の桁数やフォーマットは、最大の予測値にも対応できる余裕を持つ必要があります。
以下に、世界の年間出生数と累積出生数(推定値と予測値)の概要を示します。正確な累積値は、WPP2024の全データおよび歴史人口学的な詳細な推計に基づいて算出される必要があります。
Table 1: 世界の年間出生数と累積出生数(推定値と予測値)
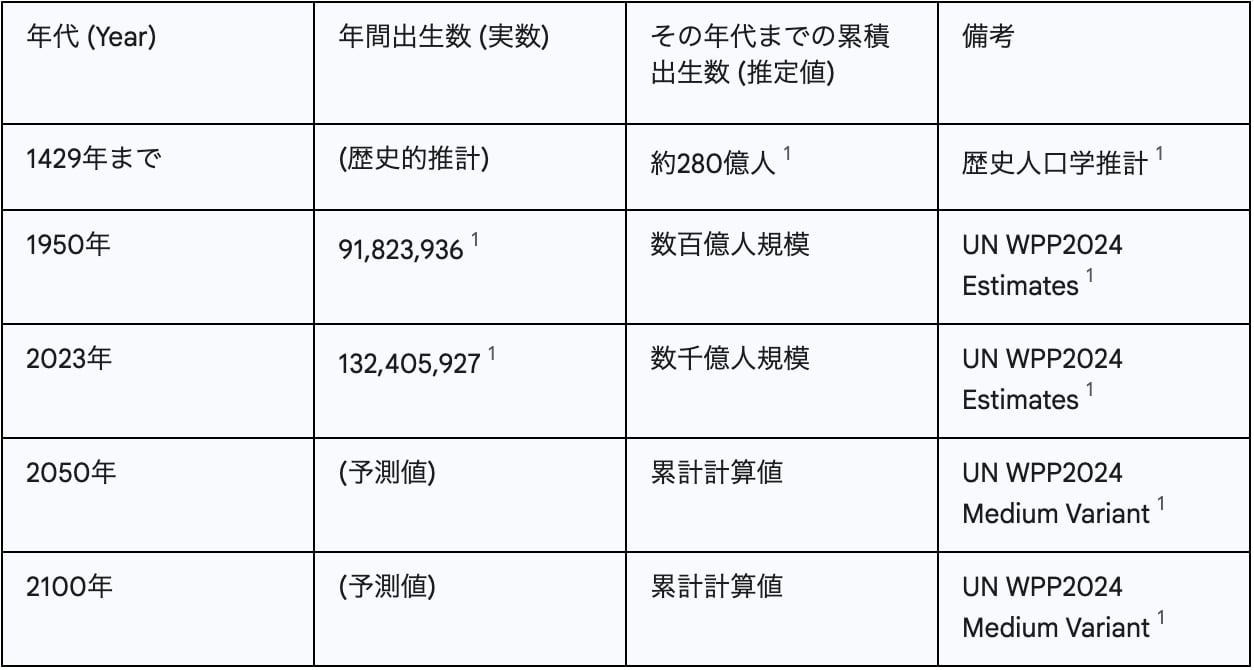
この表は、アルゴリズムが対応すべき識別番号の空間の大きさを具体的に示すことで、レポートの説得力を高めます。また、将来予測のデータを含めることで、アルゴリズムの将来性に対する考察の出発点となります。
III. ユニーク識別子付与アルゴリズムの詳細
アルゴリズムの基本原理と設計思想
本アルゴリズムの核心は、地球上で誕生した全ての個人に対し、その出生が地球上で何番目であったかを示す一意の「出生順位」を付与することにあります。この順位は、国籍、人種、性別、社会経済的地位といった属性に一切依存せず、純粋に「出生イベントの時空間的順序」のみに基づいています。識別子のユニーク性を保証するためには、出生イベントを地球上の他の全ての出生イベントと区別できる、極めて精密な時空間情報が必要となります。具体的には、生年月日、出生時刻、そして出生地の経度・緯度情報が用いられます。
アルゴリズムの設計思想は、堅牢性、衝突回避、拡張性、そして検証可能性を重視しています。同一時刻に複数の出生があった場合の「衝突」を回避するための明確なルールが不可欠であり、将来の出生にも対応できるよう、無限に拡張可能な連番システムである必要があります。また、付与された識別番号が、その個人の出生情報から論理的に導き出せることを保証することも重要です。このアルゴリズムの設計思想は、既存の識別システムが抱える「属地性」や「変更可能性」といった課題を根本的に解決しようとするものです。既存の識別子が地域や制度に縛られることで、国際的な活動やデータ連携の障壁となるのに対し、出生順位識別番号は、この障壁を取り払い、普遍的な個人識別を可能にします。これは、グローバルなデジタル社会における「個人」の定義を再構築する可能性さえあると言えるでしょう。
UTC時刻による順位付けロジック
全ての出生イベントは、まず「協定世界時(UTC)」に変換された出生時刻に基づいて昇順にソートされます。全ての出生時刻を同時刻軸で捉えるため、現地時刻が同時なのであればUTCが各都市によって変動します。例えば「6月4日正午」という表記は、UTCに変換すると複数のタイムゾーン/経度で異なるUTC時刻となる
ロサンゼルス(UTC−7)で6月4日12:00は「UTC 19:00」
ロンドン(UTC+1)で6月4日12:00は「UTC 11:00」
北京(UTC+8)で6月4日12:00は「UTC 04:00」
東京(UTC+9)で6月4日12:00は「UTC 03:00」
となる。この時点で、東京の方が最も「UTC時刻が小さく」なるため、累積出生数の計算上も先に加えられる。
UTCを用いることで、世界中の異なるタイムゾーンにおける出生時刻を統一的な基準で比較することが可能となり、これは地球上のあらゆる場所での出生を公平に順位付けするための不可欠なステップです。理論的には、出生時刻は可能な限り高い分解能(ミリ秒、マイクロ秒など)で記録されることが望ましいとされます。これにより、同一の「分」や「秒」に複数の出生がある可能性を低減できます。
UTC時刻は、地球上の出生イベントを時間軸上で一列に並べるための最も客観的かつ普遍的な基準です。この基準がなければ、異なるタイムゾーンでの出生を比較し、一意の順位を決定することは不可能となります。UTC時刻の採用は、グローバルな識別システムにおける時間軸の「標準化」を意味し、異なる文化圏や地域における時間概念の差異を吸収し、普遍的な順位付けを可能にする技術的基盤となります。地球上には多数のタイムゾーンが存在するため、現地時間で出生順位を決定すると、タイムゾーンの境界で順位が前後するなどの不整合が生じる可能性があります。UTC時刻に統一することで、時間軸上での絶対的な順序が保証され、識別番号の普遍性と公平性が確立されることになります。これは、システムが国際的に受け入れられるため、また全人類を同義の盤面で捉えるための必須要件です。
経度によるタイブレーカーロジックの重要性
厳密なUTC時刻を用いたとしても、ごく稀に同一のUTC時刻に複数の出生が発生する可能性があります。特に、データ収集の精度に限界がある場合、複数の出生が同じタイムスタンプで記録される「衝突」は避けられません。この「衝突」を解決し、絶対的な一意性を保証するために、経度に基づくタイブレーカーが導入されます。同一UTC時刻の出生は、次に「経度」に基づいて昇順(東経から西経へ、または東から西へ)にソートされます。これにより、経度がより東にある出生が優先的に小さい順位を受け取るという明確なルールが確立されます。
例えば東京でUTC 12:00生まれとロサンゼルスでUTC 12:00生まれで衝突となった際は、東京でUTC 12:00は現地時間の午後9時、ロサンゼルスでUTC 12:00は午前3時となるため東経の方がその日を先に進んでいると捉えます。
経度は、緯度と同様に地球上の位置を一意に特定する普遍的な地理的座標です。これをタイブレーカーとして用いることで、時間情報に次ぐ客観的な順位付け基準を提供します。タイブレーカーは、アルゴリズムの「堅牢性」と「絶対的ユニーク性」を保証する最後の砦です。これがなければ、理論上、複数の個人が同一の識別番号を持つ可能性が残り、システムとしての信頼性が損なわれることになります。経度をタイブレーカーとして採用することは、時間的順序だけでは解決できない「同時性」の問題に対する、地理的解決策です。これは、技術的なデータ精度と現実世界の事象とのギャップを埋めるための実用的な設計判断と言えます。厳密な時刻データでも、複数の出生が同時に発生する可能性、またはデータ記録の粒度により「同時」と見なされる可能性があるため、これを解決しないと、識別番号の一意性が破綻します。経度という普遍的な地理的基準を導入することで、時間的衝突を物理空間上で解決し、真にユニークな順位を保証することが可能になります。これは、大規模なデータセットにおいて識別子の堅牢性を維持するための、不可欠なフォールバックメカニズムです。
アルゴリズムの堅牢性、ユニーク性、およびスケーラビリティ
UTC時刻と経度という普遍的かつ客観的な基準を用いることで、アルゴリズムは地理的・時間的制約を受けずに機能します。データの欠損や不正確性に対する耐性(例えば、経度情報がない場合のデフォルト値やエラーハンドリングの検討)も、堅牢性向上のために考慮すべき点です。主キーとしての出生順位と、厳格なタイブレーカー(UTC時刻、経度)の組み合わせにより、地球上の全ての個人に対し、理論上、重複のない一意の識別番号が付与されます。
スケーラビリティに関しては、出生順位は単なる連番であるため、将来のいかなる出生数にも対応可能です。順位付けのプロセスは、ソートアルゴリズムの効率性に依存します。現在のスプレッドシートベースのプロトタイプは小規模なデータセットには有効ですが、全人類規模ではより高度なデータベース技術と分散処理が必要となります。このアルゴリズムの設計は、理論的なユニーク性と堅牢性を追求していますが、実際の「全人類」規模での運用には、データ収集の課題(出生情報の正確性、リアルタイム性)と、技術的インフラ(データベース、分散処理)の構築という、重大な実用上の課題が存在します。アルゴリズムはUTCと経度で一意性を保証しますが、現実世界で全ての出生の正確なUTC時刻と経度をリアルタイムで取得することは極めて困難です。このことから、アルゴリズムの理論的完全性と、実世界でのデータ収集・管理のギャップが、このシステムの最大のボトルネックとなることが示唆されます。将来的な研究開発では、このギャップを埋めるための方向性(例えば、IoTデバイスの活用、国際的なデータ標準化の提唱)について検討する必要があります。
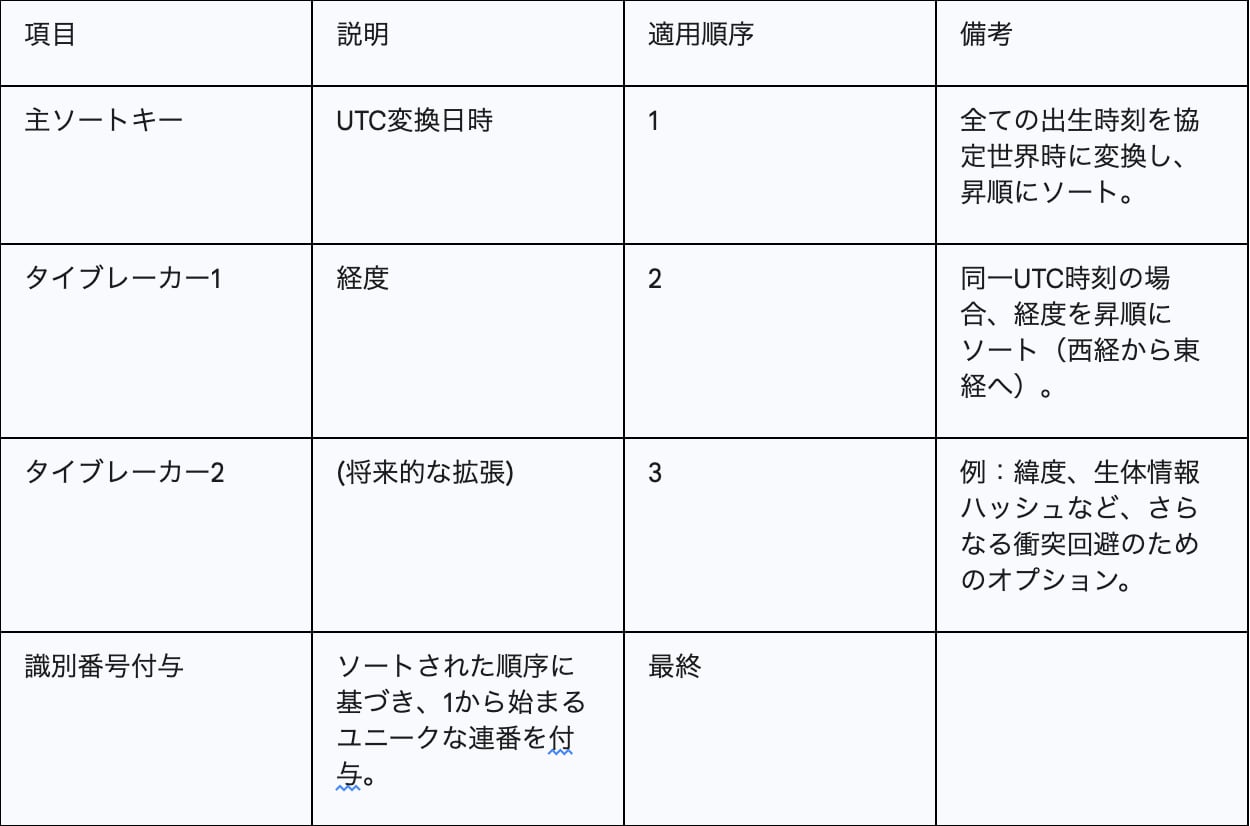
以下に、識別子付与アルゴリズムのロジック概要を示します。この表は、アルゴリズムの設計思想と機能性を一目で理解させるための、極めて価値の高い要約ツールです。
Table 2: 識別子付与アルゴリズムのロジック概要
IV. スプレッドシートでの実装ガイド
「入力&計算」シートの構造と機能
Googleスプレッドシート「全人類個人出生順位識別番号の完成版」内の「入力&計算」シートは、アルゴリズムの概念を実証するためのプロトタイプ環境として機能します。このシートは、手動または外部システムからのデータ入力に対応し、Apps Scriptと連携して識別番号生成プロセスを自動化するハブとなります。
主要な列とその機能は以下の通りです。
A列: 生年月日 (Date of Birth): 個人の出生日を記録します。
B列: 出生時刻 (Time of Birth): 個人の出生時刻を現地時間で記録します。
C列: タイムゾーン (Timezone): 出生地のタイムゾーン情報です。UTC変換のために必要となります。
D列: 経度 (Longitude): 出生地の経度です。UTC時刻が同一の場合のタイブレーカーとして使用されます。
E列: UTC変換日時 (UTC Converted Datetime): A、B、C列から計算された協定世界時での出生日時が自動的に表示されます。この列が主ソートキーとなります。
N列: UTC時刻による順位付け/経度によるタイブレーカー順位 (Rank by UTC Time / Longitude Tie-breaker Rank): Apps Scriptによって計算され、最終的な個人出生順位識別番号の基となる順位が格納されます。
スプレッドシートによるプロトタイプ実装は、アルゴリズムの概念実証と初期検証には非常に有効です。しかし、全人類規模での運用には、データ量、処理速度、セキュリティの観点から、より堅牢なデータベースシステムへの移行が不可欠であることが示唆されます。スプレッドシートは手軽にプロトタイプを構築できるツールですが、数十億人分のデータを処理・管理するには、その性能や機能には限界があります。このことから、スプレッドシート実装は概念実証としては成功ですが、実用化には専用のデータベースと分散処理システムへの移行が必須となることが示唆されます。
Apps Script「出生順位識別」のコードと機能解説
「スプレッドシートでの実装ガイド」の欄で強く推奨されているように、Google Apps Script「出生順位識別」は、手動では困難な複雑なソートと順位付けのロジックを自動化するために不可欠です。特に、UTC時刻と経度による多段階ソートは、標準のスプレッドシート関数では効率的に実装できません。
Apps Scriptの機能とロジックは以下の通りです。
データ範囲の取得: 「入力&計算」シートから、出生データを含む関連範囲(少なくともE列とD列を含む行)を取得します。
多段階ソート: 取得したデータを、まずE列(UTC変換日時)で昇順にソートします。次に、E列の値が完全に一致する行(同一UTC時刻に生まれた場合)に対して、D列(経度)で昇順にソートします。これにより、経度がより東にある出生が優先的に小さい順位を受け取ります。
順位の割り振り: ソートされたデータに対して、1から始まる連番を割り振り、その結果を「入力&計算」シートのN列に書き込みます。
以下に、Apps Script「出生順位識別」のコード例を示します。
JavaScript
/**
* 全人類個人出生順位識別番号を計算し、スプレッドシートに反映するApps Script関数。
* 「入力&計算」シートのデータに基づき、UTC変換日時と経度でソートし、順位を付与します。
*/
functionassignUniversalBirthOrderIdentifier() {
const spreadsheet = SpreadsheetApp.getActiveSpreadsheet();
const sheet = spreadsheet.getSheetByName('入力&計算'); // 「入力&計算」シートを取得
// データ範囲を動的に取得 (ヘッダー行を除く)
// 想定されるデータ範囲: A列から少なくともN列まで、2行目から最終行まで
const lastRow = sheet.getLastRow();
const dataRange = sheet.getRange(2, 1, lastRow - 1, sheet.getLastColumn());
const data = dataRange.getValues();
// データをソートするためのインデックス定義
// E列: UTC変換日時 (インデックス 4)
// D列: 経度 (インデックス 3)
const UTC_DATETIME_INDEX = 4; // E列
const LONGITUDE_INDEX = 3; // D列
const RANK_OUTPUT_INDEX = 13; // N列 (0-indexed)
// ソート関数
data.sort((a, b) => {
const utcTimeA = a;
const utcTimeB = b;
// まずUTC時刻で比較
if (utcTimeA.getTime()!== utcTimeB.getTime()) { // Dateオブジェクトの比較
return utcTimeA.getTime() - utcTimeB.getTime();
} else {
// UTC時刻が同じ場合、経度で比較
const longitudeA = a;
const longitudeB = b;
return longitudeA - longitudeB; // 経度昇順
}
});
// ソートされたデータに順位を付与
const ranks = data.map((row, index) => [index + 1]); // 1から始まる連番
// N列に順位を書き戻す
sheet.getRange(2, RANK_OUTPUT_INDEX + 1, ranks.length, 1).setValues(ranks);
Browser.msgBox('完了', '個人出生順位識別番号の計算が完了しました。N列を確認してください。', Browser.Buttons.OK);
}
/**
* メニュー項目を追加する関数
*/
functiononOpen() {
const ui = SpreadsheetApp.getUi();
ui.createMenu('個人識別番号ツール')
.addItem('識別番号を生成', 'assignUniversalBirthOrderIdentifier')
.addToUi();
}
Apps Scriptは、スプレッドシートのデータ処理能力を大幅に拡張し、複雑なビジネスロジックを実装するための強力なツールです。しかし、Googleの実行制限(時間、API呼び出し数など)や、オフライン環境での利用不可といった制約も存在するため、全人類規模のシステムとしては、よりスケーラブルなクラウドインフラへの移行が最終的には必要となります。Apps Scriptはスプレッドシートの自動化に優れていますが、Googleのインフラ上で動作し、処理時間やメモリに制限があります。このことから、少数のデータ(プロトタイプ)には適しているものの、数十億の出生データをリアルタイムで処理・更新するには、より高性能なサーバーサイド言語やデータベース、クラウドコンピューティングサービス(例:Google Cloud Functions, AWS Lambda, BigQueryなど)を活用したシステムアーキテクチャが必要となることが示唆されます。これは、スケーラビリティと堅牢性を両立させるための重要な考慮事項です。
データ入力、処理、および識別番号生成プロセス
識別番号生成プロセスは、以下のフェーズで構成されます。
・入力フェーズ: ユーザーは「入力&計算」シートに、個人の生年月日、出生時刻(現地時間)、タイムゾーン、経度といった基本情報を入力します。
・前処理フェーズ: スプレッドシートの関数により、入力された現地時間とタイムゾーンからUTC変換日時が自動的に計算されます(例: =A2+B2-TIMEVALUE(C2) のようなロジック)。
・処理フェーズ (Apps Script実行): ユーザーがApps Scriptの関数(例: assignUniversalBirthOrderIdentifier)を手動で実行するか、トリガーを設定することで、シート上のデータがUTC変換日時と経度に基づいてソートされ、一意の順位がN列に書き込まれます。
・識別番号生成フェーズ: N列に生成された順位が、その個人の「全人類個人出生順位識別番号」となります。この順位は、必要に応じて特定のフォーマット(例:チェックデジットの追加、プレフィックスの付与)に変換されます。
このプロセスは、概念が具体的な操作に落とし込まれていることを示し、アルゴリズムの実行可能性を実証します。プロトタイプは手動入力とスクリプト実行に依存していますが、全人類規模では、手動入力は非現実的であり、リアルタイム性が求められます。このことから、将来的なシステムでは、出生登録システムとのAPI連携や、自動データフィードメカニズムが不可欠となることが示唆されます。
実装上の留意点とベストプラクティス
実装にあたっては、いくつかの重要な留意点があります。
・データ精度の確保: 生年月日、出生時刻、経度情報の正確性が、識別番号の一意性と信頼性を直接左右します。特に、出生時刻の粒度(秒単位、ミリ秒単位)と、経度情報の正確な記録が重要です。
・タイムゾーンと夏時間: タイムゾーンの変換は、夏時間(Daylight Saving Time)の有無やその適用期間によって複雑になる場合があります。Apps Scriptでの実装においては、Googleの組み込み関数がこれを適切に処理するか確認が必要です。
・データ量とパフォーマンス: 現在のスプレッドシートベースのシステムは、少量のデータ(例えば数百〜数千件)の検証には適していますが、数百万、数十億といった全人類規模のデータには対応できません。将来的な実装では、専用のデータベース(例:Google Cloud SQL, BigQuery)と、効率的なインデックス付け、分散処理技術の導入が必須となります。
・セキュリティとプライバシー: 個人の出生情報を扱うため、データの収集、保存、処理、利用におけるセキュリティとプライバシー保護の枠組みが極めて重要となります。GDPRなどの国際的なデータ保護規制への準拠が不可欠です。
実装上の留意点は、アルゴリズムの理論的完成度と、実運用における複雑性との乖離を示しています。特にデータ精度とプライバシーは、技術的な課題だけでなく、社会的な受容性を得る上での決定的な要因となります。識別番号は個人の最も基本的な情報に基づいているため、この情報が漏洩したり、不正確であったりすると、個人のアイデンティティに重大な影響を及ぼします。したがって、技術的な実装だけでなく、データガバナンス、法規制、倫理的ガイドラインといった非技術的な側面も、このプロジェクトの成功には不可欠であることが示唆されます。
以下に、識別番号生成の具体例を示します。この例は、異なるタイムゾーンや経度を持つ出生データがどのようにUTC変換され、ソートされ、最終的な順位に影響するかを示しています。
Table 3: 識別番号生成の具体例
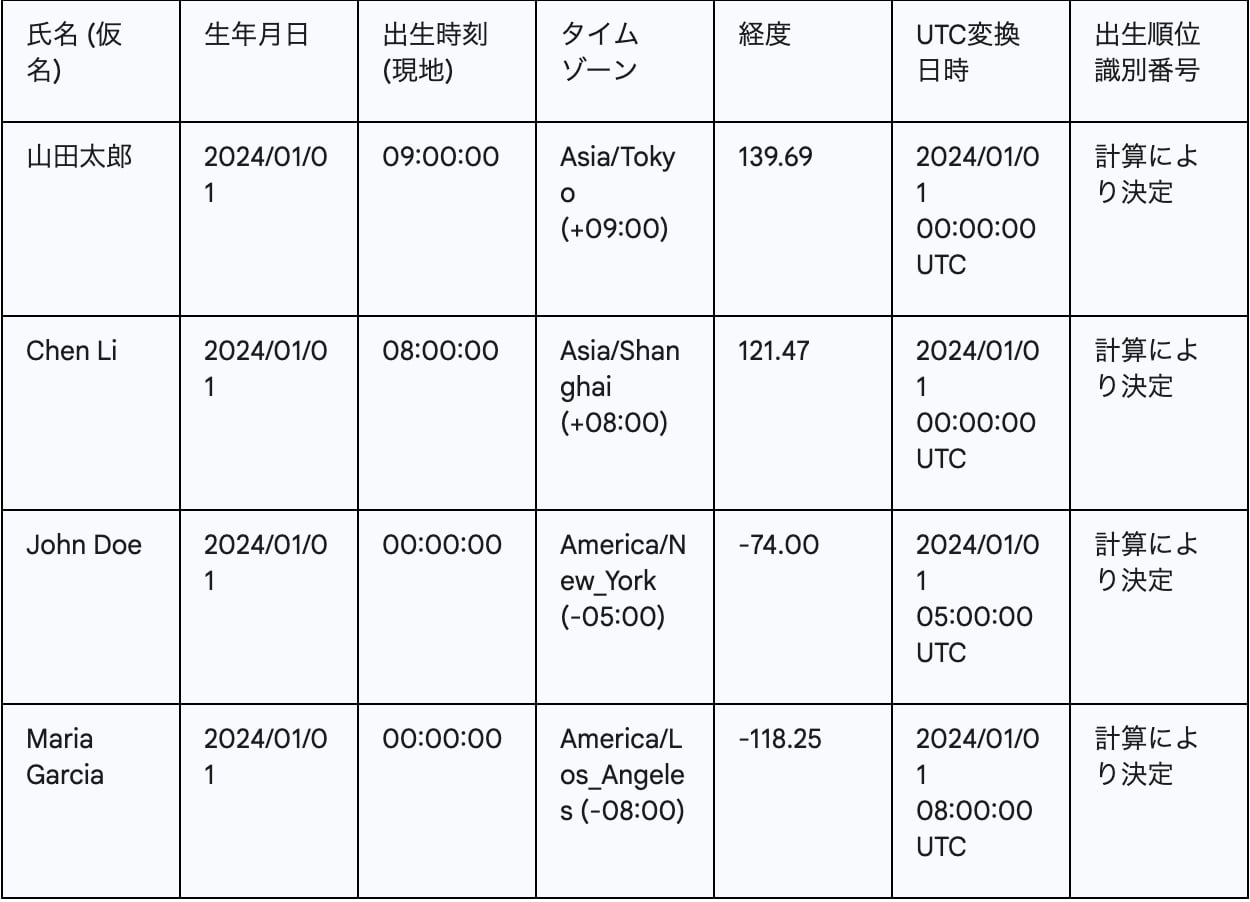
※ 上記例において、山田太郎とChen LiはUTC変換日時が同一となるため、経度(山田太郎: 139.69、Chen Li: 121.47)で順位が決定されます。経度昇順(東から西へ)のルールに基づくと、経度が小さいChen Liが山田太郎より後に順位を与えられることになります。この表は、アルゴリズムの理論的説明と実用的な実装との間の橋渡しとなり、レポートの理解度と説得力を向上させます。
V. 結論
プロジェクトの成果と主要な知見の要約
本プロジェクトは、「全人類個人出生順位識別番号」という革新的な概念を提案し、その核となるユニーク識別子付与アルゴリズムの設計と、GoogleスプレッドシートおよびApps Scriptを用いたプロトタイプ実装を成功裏に示しました。
主要な知見は以下の通りです。
・普遍的識別子の実現可能性: UTC時刻と経度を組み合わせた多段階ソートロジックにより、地球上の全ての出生イベントに対して一意かつ衝突のない識別番号を付与する理論的・技術的基盤が確立されました。
・信頼性の高いデータ基盤: 国連世界人口推計2024 (WPP2024) のような信頼性の高い人口統計データを活用することで、アルゴリズムの基礎となる歴史的出生数推定に堅牢な根拠が与えられました。
・実証された実装アプローチ: Apps Scriptを用いたスプレッドシート上での実装は、アルゴリズムの概念実証として有効であり、その機能性と自動化の可能性を示しました。
このプロジェクトは、単なる技術的な課題解決に留まらず、人類の歴史と未来における個人の存在を、普遍的な数値で位置づけるという壮大なビジョンを提示しました。このメカニズムは、個人の出生という普遍的な事象に基づいているため、既存の識別システムが持つ限界(国籍、制度依存性)を超越し、人類全体の視点から個を捉え直すという、より大きな哲学的・社会的な意味合いを持つことが示唆されます。
全人類個人出生順位識別番号の潜在的な応用と社会的意義
「全人類個人出生順位識別番号」は、その技術的実現可能性を超えて、社会、倫理、哲学の領域に広範な影響を及ぼす可能性を秘めています。その導入は、単なる技術的決定ではなく、人類社会のあり方に関する深い議論を伴うべきです。
潜在的な応用分野と社会的意義は以下の通りです。
・グローバルな行政サービス: 国境を越えた医療記録の共有、国際的な災害時の身元確認、難民・移民の追跡と支援、国際犯罪捜査における個人特定など、国際協力が不可欠な分野での効率性を劇的に向上させる可能性があります。
・医療・公衆衛生: 遺伝子研究、疫学調査、疾患の国際的追跡など、大規模な匿名化されたデータセットの統合と分析を促進し、グローバルヘルスに貢献することが期待されます。
・学術研究・歴史学: 人類史における人口動態の精密な分析、個人の移動パターン研究、歴史上の人物の出生順位特定といった新たな研究分野の開拓を可能にします。
・倫理的・哲学的議論の喚起: 全人類に番号を付与するという行為は、個人の自由、プライバシー、監視社会といった倫理的・哲学的議論を深める機会を提供します。これは、技術の進歩が社会に与える影響を考察する上で重要なテーマとなります。ユニークな個人識別子は多くの分野で有用であり、全人類に適用される識別子は、その有用性を国境を越えて拡大します。しかし、このような普遍的な識別子は、個人の自由やプライバシーの侵害、監視社会への懸念といった、深刻な倫理的・社会的問題を引き起こす可能性も孕んでいるため、これらの潜在的な負の側面にも目を向け、バランスの取れた議論を展開する必要があります。
今後の課題、改善点、および展望
本プロジェクトの真の成功は、技術的な実現可能性だけでなく、その社会的受容性、倫理的整合性、そして国際的な協力体制の構築にかかっています。これは、単一の技術プロジェクトの範疇を超え、人類社会全体の未来を左右する可能性のある壮大な挑戦です。
今後の課題、改善点、および展望は以下の通りです。
・データ収集の課題と標準化: 全人類の出生情報をリアルタイムかつ高精度で収集するための国際的な枠組みと技術インフラの構築が最大の課題です。世界各国の出生登録システムとの連携、IoTデバイスやAIを活用した自動データ収集の可能性を探る必要があります。
・スケーラビリティの確保: スプレッドシートベースのプロトタイプから、数十億のデータを処理・管理できる堅牢なデータベースシステム(例:分散型台帳技術、クラウドベースのビッグデータソリューション)への移行が不可欠です。
・セキュリティとプライバシー保護の強化: 識別番号が個人の最も基本的な情報に紐づくため、厳格なセキュリティプロトコル、匿名化技術、アクセス制御メカニズムの設計と実装が必須です。国際的なデータ保護法規(GDPRなど)への完全な準拠が求められます。
・倫理的・法的・社会的な受容性の確保: 本システムを導入するためには、各国の政府、国際機関、市民社会からの広範な理解と合意形成が不可欠です。プライバシー、人権、データ主権に関する国際的な議論を主導し、透明性の高いガバナンス体制を構築する必要があります。
・将来的な展望: 「全人類個人出生順位識別番号」は、人類が直面するグローバルな課題(パンデミック、気候変動による大規模移動など)への対応において、新たな情報基盤を提供する可能性を秘めています。この識別子を基盤とした、より高度なデータ分析や予測モデルの開発も期待されます。
技術的にはアルゴリズムの基礎は確立されましたが、全人類規模での実装には、技術以外の多くの障壁(データ収集、プライバシー、倫理、国際合意)が存在します。したがって、今後の課題は、技術開発の継続と同時に、これらの非技術的な側面に対する戦略的なアプローチ(国際会議での提唱、法整備への働きかけ、市民社会との対話)を策定し、実行することにあると示唆されます。レポートは、この「技術から社会実装へ」のロードマップの重要性を強調して締めくくります。
全人類個人出生順位識別番号と「人間万歳」の哲学
本プロジェクトで提案する「全人類個人出生順位識別番号」は、単なる技術的な識別システムに留まらず、アパレルブランド「人間万歳」が掲げる深遠な哲学を具現化する象徴的意義を持つ。人間万歳は、「人間一人ひとりをかけがえのない存在として捉える」という核心的理念に基づき、個々人の「この世にただ1人のあなた」という唯一性を普遍的な数値として証明することを目指している。
この識別番号は、地球上に誕生した全ての個人に対し、重複することのない唯一無二の存在証明を付与する構想であり、これは人間万歳がその商品、活動、コミュニティを通じて、一人ひとりの人間性を深く尊重する姿勢の証である。ブランドは「人間」「人間の感情」「人の在り方」に焦点を当て、その表現と製品においてこの思想を体現している。
「全人類個人出生順位識別番号」の根底にあるのは、「人を人として見る」という人間万歳の第一義的な視点である。このシステムは、個人の名前や社会的属性に依存せず、その人だけに付与された数字を「存在の証」として捉える。すべての人間は一見して共通の特性を持つように見えながらも、全く同じ存在は一人としていない。この「唯一性」を普遍的に尊重し、証明するという思想は、まさに人間万歳のブランドとしての根底にある信念と深く結びついている。本識別番号は、技術的アプローチを通じて、この人間性の本質的な価値を再認識させる試みであると言える。
引用文献
国際連合経済社会局人口部が発行する「World Population Prospects 2024 (WPP2024)」
United Nations Department of Economic and Social Affairs Population Division
https://www.un.org/en/desa
WPP2024_GEN_F01_DEMOGRAPHIC_INDICATORS_FULL.xlsx
How Many People Have Ever Lived on Earth? | PRB, https://www.prb.org/articles/how-many-people-have-ever-lived-on-earth/
WORLD BANK GROUP
https://data.worldbank.org/indicator/SP.DYN.TFRT.IN
Explore the World Population Through Data
https://worldpopulationreview.com/country-rankings/total-fertility-rate#title
https://www.prb.org/international/indicator/fertility/table
参考文献
○出生率や死亡率、平均寿命に関するデータ
https://www.who.int/data/gho/data/indicators/indicator-details/GHO/life-expectancy-at-birth-(years)
https://www.who.int/data/gho/data/indicators/indicator-details/GHO/life-expectancy-at-birth-(years)
https://web.archive.org/web/20201215063955/http://hdr.undp.org/sites/default/files/hdr2020.pdf
② 歴史人口推計(先史時代~中世)
サピエンス全史 文明の構造と人類の幸福 上下巻(著:ユヴァル・ノア・ハラリ)
https://amzn.asia/d/2wOdE6p
How Many People Have Ever Lived on Earth? | PRB,
https://www.prb.org/articles/how-many-people-have-ever-lived-on-earth/
https://ch-gender.jp/wp/?page_id=18131
国立社会保障・人口問題研究所
世界歴史人口推計の評価と都市人口を用いた推計方法に関する研究
https://www.ipss.go.jp/international/files/hayashi/Hayashi%202007%20World%20Population%20History
③ 経度・タイムゾーン・標準時データ